- Published on
Data Engineering Zoomcamp, Week 5: Apache Spark
As data sources have expanded exponentially, the demand for increased computational power and memory has surged. Apache Spark harnesses the power of distributed computing, allowing us to perform complex transformations on vast datasets by parallelizing tasks across multiple worker nodes. In Week 5 of the Data Engineering Training Camp (DTC), we learned about the mechanics of Spark, exploring its ecosystem and demonstrating how it efficiently processes large-scale data in a distributed manner. With this particular module, I discovered the pains in setting up and managing Spark as an Open Source System (OSS). This experience highlights why particular COSS solutions, such as Databricks, are so popular as they manage these operational complexities for us.
- Prerequisites
- Spark
Prerequisites
Before we get into the specifics of Spark, it's essential to set up a local environment that can mimic a distributed Spark cluster. One of the most efficient ways to do this is by using Docker, which allows for the isolation and management of the Spark environment without affecting the host system.
Running Spark in a local Docker container
While setting up my Spark cluster on a Windows machine, I encountered an issue related to Spark's version compatibility, particularly with Pandas. The Spark version 3.3.2 we are using depends on the iteritems function from Pandas when creating a Spark DataFrame, a method that has been deprecated since version 1.5.0. This incompatibility resulted in an AttributeError:
spark.createDataFrame(df_pandas).schemaI am getting AttributeError: 'DataFrame' object has no attribute 'iteritems'
To resolve this, I upgraded PySpark to version 3.5.1 and updated Pandas to version 2.0.1, which restored compatibility and functionality. If you prefer to continue using PySpark version 3.3.2, it's necessary to revert Pandas to version 1.5.3 to avoid this issue.
Later in the module, we will utilize Google's Dataproc service, a fully managed cloud solution for running Apache Spark. Dataproc will help us bypass the hassle of managing these dependencies on our local machine.
Dockerfile
The Dockerfile below sets up an Ubuntu-based environment with all the necessary dependencies to run Spark, including Java, Python, and Spark itself. Additionally, it installs Jupyter Lab and other Python libraries to aid in the development and execution of Spark applications. Add these files to the week 5 directory in your repo and run docker compose up to build your container. You should then be able to access a Jupyter lab with all of the Jupyter notebooks from the week 5 module in the web via http://localhost:8888.
# Use Ubuntu 20.04 LTS as base image
FROM ubuntu:20.04
# Avoid prompts from apt and set timezone
ENV DEBIAN_FRONTEND=noninteractive
ENV TZ=UTC
# Install necessary packages
RUN apt-get update && \
apt-get install -y wget tar git curl gnupg && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
# Set environment variables for Java, Spark, and Conda
ENV JAVA_HOME=/opt/jdk
ENV SPARK_HOME=/opt/spark
ENV PATH="/opt/conda/bin:${JAVA_HOME}/bin:${SPARK_HOME}/bin:${PATH}"
# Install OpenJDK 11
RUN wget https://download.java.net/java/GA/jdk11/9/GPL/openjdk-11.0.2_linux-x64_bin.tar.gz -O /tmp/openjdk-11.tar.gz && \
mkdir -p "$JAVA_HOME" && \
tar --extract --file /tmp/openjdk-11.tar.gz --directory "${JAVA_HOME}" --strip-components 1 && \
rm /tmp/openjdk-11.tar.gz
# Install Miniconda
RUN wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O /tmp/miniconda.sh && \
bash /tmp/miniconda.sh -b -p /opt/conda && \
rm /tmp/miniconda.sh
# Install Python 3.8, PySpark 3.3.2, Jupyter Lab, and Pandas 2.0.1
# Note: Update PySpark to match the Spark version if necessary
RUN conda install -y python=3.8 && \
pip install pyspark==3.5.1 jupyterlab pandas==2.0.1
# Install Spark 3.5.1
RUN wget https://archive.apache.org/dist/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz -O /tmp/spark-3.5.1-bin-hadoop3.tgz && \
mkdir -p "$SPARK_HOME" && \
tar xzfv /tmp/spark-3.5.1-bin-hadoop3.tgz --strip-components=1 -C "$SPARK_HOME" && \
rm /tmp/spark-3.5.1-bin-hadoop3.tgz
# Download and add the GCS connector jar to the Spark jars directory
RUN wget https://storage.googleapis.com/hadoop-lib/gcs/gcs-connector-latest-hadoop2.jar -O $SPARK_HOME/jars/gcs-connector-latest-hadoop2.jar
# Add the Google Cloud SDK distribution URI as a package source
RUN echo "deb [signed-by=/usr/share/keyrings/cloud.google.gpg] http://packages.cloud.google.com/apt cloud-sdk main" | tee /etc/apt/sources.list.d/google-cloud-sdk.list && \
curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key --keyring /usr/share/keyrings/cloud.google.gpg add -
# Install Google Cloud SDK
RUN apt-get update && \
apt-get install -y google-cloud-sdk && \
rm -rf /var/lib/apt/lists/*
# Set working directory
WORKDIR /opt/spark/work-dir
# Expose ports for Jupyter Lab and Spark UI
EXPOSE 8888 4040 8080 8081 18080
# Start Jupyter Lab by default
CMD ["jupyter", "lab", "--ip='0.0.0.0'", "--port=8888", "--no-browser", "--allow-root", "--NotebookApp.token=''", "--NotebookApp.password=''"]
Docker Compose
The docker-compose.yml configuration facilitates the simultaneous running of Jupyter notebooks and the Spark UI in Docker. Recall back to Week 1, when we used docker-compose to configure our PostgreSQL database as well as pgadmin4, allowing our databse to persist along side our database management tool. The setup below ensures that each Spark session can be independently monitored through a dedicated Spark UI port.
We've allocated multiple ports for the Spark UI in the docker-compose.yml to accommodate multiple Spark sessions running concurrently. Each session or application initiated in Spark gets its own UI port for monitoring and management. For example, the first Spark application might use port 4040 for its UI, and subsequent applications will use incrementally numbered ports like 4041, 4042, and so on.
Here's a snippet of Python code to illustrate how a Spark session might be initiated, with the application name set to "test":
spark = SparkSession.builder \
.master('local[*]') \
.appName("test") \
.getOrCreate()
In this setup, if "test" is the first application started, its Spark UI will be accessible on port 4040. If another session, say with the app name "test2", is launched while "test" is still running, "test2" would then use the next available port, which would be 4041, and so forth. This configuration ensures that each Spark application's UI is isolated and accessible for monitoring and troubleshooting. Go to http://localhost:4040 on the web to access the Spark UI.
version: '3'
services:
spark-jupyter:
build: .
image: spark_jupyter_lab:latest # Name and tag the image
ports:
- "8888:8888" # Jupyter Lab, for accessing notebooks
- "7077:7077" # Spark Master, for worker node registration and job submissions in standalone mode
- "4040-4044:4040-4044" # Range for Spark UI, allows monitoring of multiple Spark jobs
- "8080:8080" # Spark Master UI, for monitoring the Spark cluster
- "8081:8081" # Spark Worker UI (optional), for detailed worker monitoring if separate worker nodes are used
- "18080:18080" # Spark History Server, for reviewing job histories
volumes:
- ./code:/opt/spark/work-dir # Mount the 'code' directory to the container's work directory
Spark
Introduction to Spark Environment Setup
After preparing the Docker environment for Spark, the next step is to establish a local Spark cluster. This process involves initiating the Spark master and worker services, which will allow for the execution of Spark jobs in a clustered environment.
Transitioning from Local to Cluster Mode
Before we explore setting up a Spark cluster, it's important to note that for the majority of scripts in this module, we've initialized Spark in local mode by configuring the Spark session with .master("local[*]"). This setting runs Spark on a single machine and uses all available cores, simulating a distributed environment on a single host. This mode is ideal for beginners to understand Spark's functionality without the overhead of managing a distributed cluster.
However, to better mimic a production environment and understand how Spark operates in a clustered setting, we'll set up a standalone Spark cluster using Docker. This approach provides a closer approximation to how Spark runs in a distributed environment, allowing for multiple worker nodes and more realistic resource management.
Setting Up a Local Spark Cluster with Docker
We can setup a standalone cluster by going into our spark directory and utilizing the following shell scripts spark provides. Within our docker container, Spark is located in /opt/spark/ directory. Open a terminal in our running docker container and we will use the following commands:
- ./sbin/start-master.sh
- ./sbin/start-worker.sh
- ./bin/spark-submit
- Start the Spark Master: Open a terminal in the running Docker container and execute the following command to start the Spark master service:
../sbin/start-master.sh
This command launches a local standalone Spark master at http://localhost:8080/. If you are using the Dockerfile and docker-compose file from earlier, the Spark cluster will display as Spark Master at spark://<container-id>:7077, where <container-id> is the hostname generated for your Docker container (e.g., f22e994ff136).
- Start a Spark Worker: Next, start a worker node that will execute the Spark jobs by running:
../sbin/start-worker.sh `<master-spark-URL>`
Replace <master-spark-URL> with the master's URL obtained in the previous step. For example:
../sbin/start-worker.sh spark://f22e994ff136:7077
After initiating these services, you can access the UI for both the Master and Worker nodes. The Master UI is available at http://localhost:8080, which provides an overview of the cluster, and if you have configured additional ports for worker UIs, they can typically be accessed starting at http://localhost:8081.
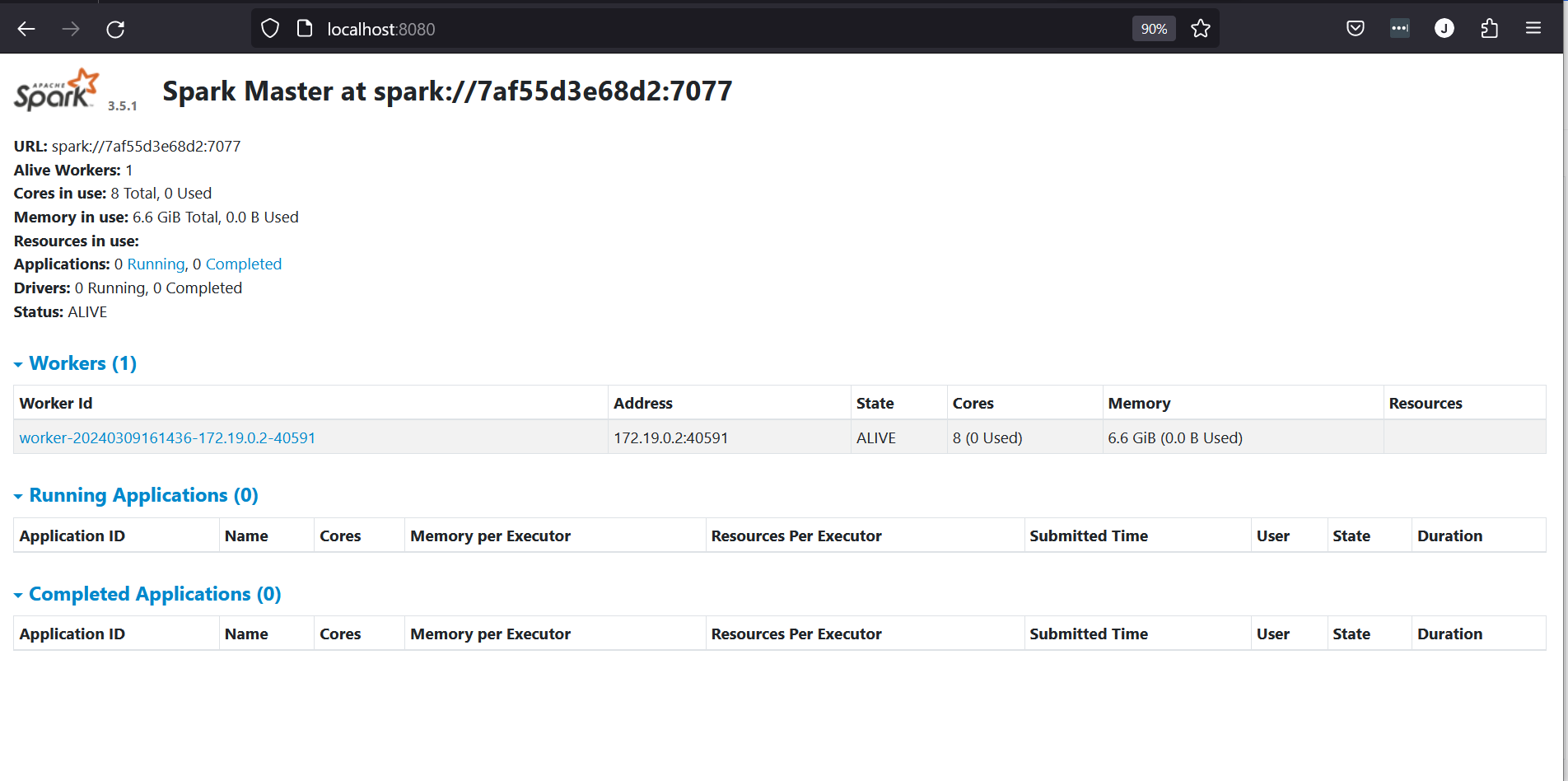
By setting up a local Spark cluster in Docker, you get a practical, scalable environment for developing and testing Spark applications, closely mirroring the configurations used in production settings. In the section below, we will utilize our newly created local spark cluster to run 06_spark_sql.py with the spark-submit command.
Spark's Core Concepts
RDDs (Resilient Distributed Datasets)
RDDs, or Resilient Distributed Datasets, are a fundamental concept in Apache Spark, representing a distributed collection of objects. Internally, Spark DataFrames are built upon RDDs, introducing an additional layer of abstraction that facilitates more efficient data handling and processing.
Transformations and Actions
Spark operations are categorized into transformations (like map, filter, groupBy) which create new RDDs or DataFrames without immediate computation, and actions (like count, collect, saveAs) which trigger computations and produce results.
Lazy Evaluation
Spark utilizes lazy evaluation to optimize processing efficiency. Computations on RDDs or DataFrames are delayed until an action is triggered, allowing Spark to optimize the overall data processing workflow.
Example of Reading Data into a Dataframe
Consider the following code block where we read a Parquet file from a Google Cloud Storage (GCS) bucket into a Spark DataFrame. Upon executing df.take(5), Spark returns an array of the first five rows from the DataFrame:
from pyspark.sql import SparkSession
# Initialize a Spark session
spark = SparkSession.builder \
.appName("Read Parquet files from GCS") \
.getOrCreate()
# Configuration for accessing the GCS bucket
bucket_name = "your-bucket-name"
path = f"gs://{bucket_name}/ny_taxi_data/service=green/year=2019/month=10"
spark._jsc.hadoopConfiguration().set("google.cloud.auth.service.account.json.keyfile", "path-to-your-credentials.json")
# Reading the Parquet file into a DataFrame
df = spark.read.parquet(path)
# Displaying the first 5 rows of the DataFrame
df.take(5)
Understanding Abstraction in Computer Science
In the case of the example above, a DataFrame in Apache Spark acts as an abstraction built on top of RDDs, streamlining data operations and manipulation.
"Abstraction, as used in computer science, is a simplified expression of a series of tasks or attributes that allow for a more defined, accessible representation of data or systems. In computer programming, abstraction is often considered a means of “hiding” additional details, external processes and internal technicalities to succinctly and efficiently define, replicate and execute a process."
Similar to Spark's DataFrames, the Pandas library in Python provides an abstraction for data manipulation and analysis, simplifying the process of working with structured data.
Converting DataFrame to an RDD
In PySpark, converting a DataFrame to an RDD is accomplished by invoking the .rdd attribute. This conversion allows access to lower-level RDD operations, such as map and mapPartitions. Below is an example demonstrating this conversion:
from pyspark.sql import SparkSession
# Initialize a Spark session
spark = SparkSession.builder.appName("example").getOrCreate()
# Create a Spark DataFrame
data = [1, 2, 3, 4, 5]
df = spark.createDataFrame(data, "int").toDF("number")
# Show the original DataFrame
df.show()
# Convert the DataFrame to an RDD
rdd = df.rdd
# Resulting RDD
# [Row(number=1), Row(number=2), Row(number=3), Row(number=4), Row(number=5)]
# Use the map function to square each number
squared_rdd = rdd.map(lambda row: row['number'] ** 2)
# Collect and show the results
squared_numbers = squared_rdd.collect()
print(squared_numbers)
#Result of implementing map function on our RDD:
# [1, 4, 9, 16, 25]
Although converting a DataFrame to an RDD provides access to lower-level functions, it bypasses the optimizations inherent to DataFrames. Therefore, this operation should be used judiciously, considering the potential performance implications.
Integrating with Google Cloud Storage (GCS)
To access Google Cloud Storage (GCS) from your Spark application, authenticate using a service account JSON keyfile. Add the following line to your 06_spark_sql.py script:
import argparse
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
parser = argparse.ArgumentParser()
parser.add_argument('--input_green', required=True)
parser.add_argument('--input_yellow', required=True)
parser.add_argument('--output', required=True)
args = parser.parse_args()
input_green = args.input_green
input_yellow = args.input_yellow
output = args.output
spark = SparkSession.builder \
.appName('test') \
.getOrCreate()
# Auth to GCS
spark._jsc.hadoopConfiguration().set("google.cloud.auth.service.account.json.keyfile","/opt/spark/work-dir/dtc-de-zoomcamp-12345-678910.json")
# Remainder of script...
Open a terminal in your Docker container and set the necessary environment variables:
export MASTER_URL="spark://<container-id>:7077"
export BUCKET_NAME="your-cloud-bucket"
export GREEN_PATH="gs://${BUCKET_NAME}/ny_taxi_data/service=green/year=2019/month=*"
export YELLOW_PATH="gs://${BUCKET_NAME}/ny_taxi_data/service=yellow/year=2019/month=*"
export OUTPUT_PATH="gs://${BUCKET_NAME}/ny_taxi_data/report/revenue/year=2019"
Execute the Spark job on your local cluster using spark-submit:
spark-submit \
--master="${MASTER_URL}" \
06_spark_sql.py \
--input_green="${GREEN_PATH}" \
--input_yellow="${YELLOW_PATH}" \
--output="${OUTPUT_PATH}"
Access the Spark job's UI at http://localhost:4040 during runtime. Note that this UI is only active while the Spark application is running.
Google Dataproc
To submit a Spark job via Google Dataproc, first create a cluster in the Dataproc web UI.
Submitting a Job with Google Cloud SDK
After setting up your Dataproc cluster, use the Google Cloud SDK CLI to submit your Spark job. Ensure 06_spark_sql.py is uploaded to your GCS bucket (e.g., gs://your-bucket/code/).
- Auth to Google Cloud
gcloud auth login
- Set Google Project ID
gcloud config set project <project-id>
- Submit the Spark Job
gcloud dataproc jobs submit pyspark \
--cluster=de-zoomcamp-cluster \
--region=us-central1 \
gs://mage-zoomcamp-bucket/ny_taxi_data/code/06_spark_sql.py \
-- \
--input_yellow=gs://mage-zoomcamp-bucket/ny_taxi_data/service=yellow/year=2019/month=* \
--input_green=gs://mage-zoomcamp-bucket/ny_taxi_data/service=green/year=2019/month=* \
--output=gs://mage-zoomcamp-bucket/ny_taxi_data/report/revenue/year=2019