- Published on
Data Engineering Zoomcamp, Week 2
In Week 2 of the DTC Data Engineering Zoomcamp, we learned about the the art of workflow orchestration using Mage. Imagine being a chef, where every step in a recipe is crucial to the final dish. Similarly, in data engineering, orchestration is about carefully coordinating tasks to ensure efficiency and effectiveness. This concept, eloquently described in 'Fundamentals of Data Engineering: Plan and Build Robust Data Systems' by Joe Reis, Matt Housley, et al., as 'the process of coordinating many jobs to run as quickly and efficiently as possible on a scheduled cadence,' is a cornerstone of our field. It involves strategically sequencing and managing tasks to optimize performance and output, much like preparing a complex dish.
For instance, consider the steps in crafting my favorite pasta dish, Penne alla Vodka: from boiling water to the final garnish of parmesan and basil. Each step relies on the previous one, akin to how workflow orchestration operates in data engineering. In this week's module, Workflow Orchestration, Matt Palmer, an author and Relations Developer at Mage, walks us through the creation of an ETL pipeline with Mage. You can find links to the original videos in the Week 2 readme. Our journey starts with extracting data (New York Taxi data, in our case), transforming it for clarity and usefulness, and finally, exporting it to a PostgreSQL database and a Google Cloud Storage bucket. Just as the final step in our pasta recipe brings all the ingredients together, our data, now processed and refined, is ready to be served.
Before we start, be sure to check out the DataTalksClub website here where you will find links to a slack channel and other resources that will help in your journey to becoming a data engineer.
Lastly, you can find the github repository for this specific course here. Be sure to star the repository!
- Configuring Mage
- Building an ETL Pipeline with Mage (postgreSQL)
- Building an ETL Pipeline with Mage (Google Cloud)
- Scheduling a Workflow (Automating Pipeline)
- Parameterization
- In Summary
- Looking Ahead
Configuring Mage
Prior to getting into some of the key components of Mage, we need to setup our environment. If you haven't already, you'll need to clone the Mage Zoomcamp repository provided so we can setup our environment locally.
Assuming you've already completed the week 1 modules, starting up the environment should be pretty straightforward, but you can refer to the Readme file in the Mage repo if you run into any issues.
- Clone repo to vscode
- Open a terminal in your local repo directory
- Run the following commands
docker compose build
Followed by
docker compose up
- Navigate to http://localhost:6789 in your browser
Now we can start building our pipeline!
Building an ETL Pipeline with Mage (postgreSQL)
Mage has a few components that make the code we write highly reusuable. These are what Mage refers to as Blocks. There are three type of blocks that we can leverage when creating a pipeline:
- Data Loader
- Transformer
- Data Exporter
The first pipeline we built in the Week 2 module is an ETL pipeline using blocks to load the yellow taxi data from this github repo, transform the data and export the data into a postgres database within our docker container. The resulting DAG should look something like the screenshot below.
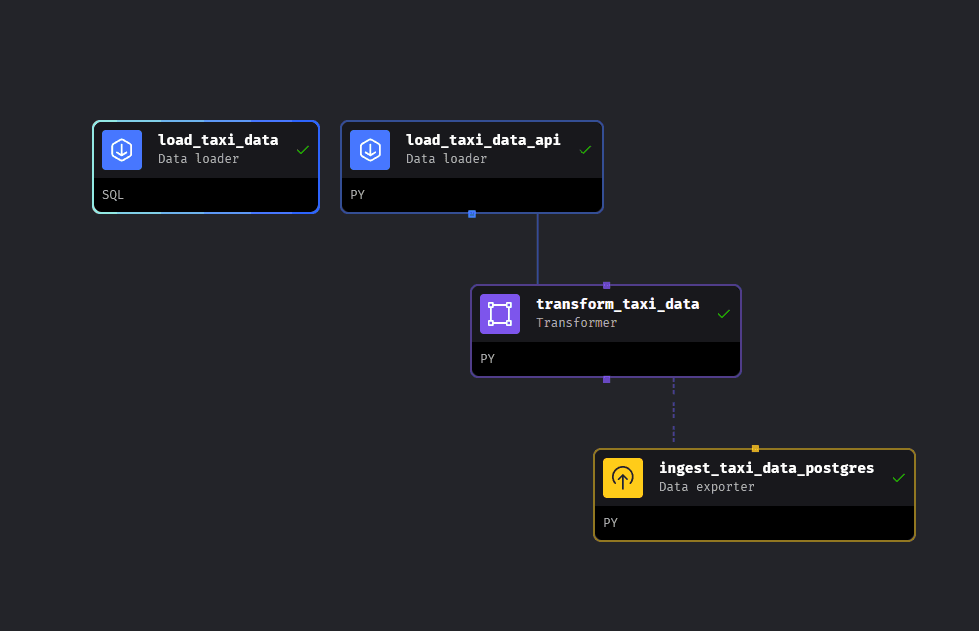
Configuring postgreSQL connection
Before we can get into the pipeline code, we need to first setup a yaml profile in the io_config.yml file. This is where we define environmental variables that will allow us to authenticate to cloud providers, databases, etc. In the instance of the pipeline we are building, we need to define how the pipeline will authenticate to our postgreSQL database that is running as a service in our docker container, alongside Mage. Navigate over to the io_config.yml file in either vscode or the Mage GUI in your web browser. At the bottom of the file, we need to add the following line:
dev:
POSTGRES_CONNECT_TIMEOUT: 10
POSTGRES_DBNAME: "{{ env_var('POSTGRES_DBNAME') }}"
POSTGRES_SCHEMA: "{{ env_var('POSTGRES_SCHEMA') }}"
POSTGRES_USER: "{{ env_var('POSTGRES_USER') }}"
POSTGRES_PASSWORD: "{{ env_var('POSTGRES_PASSWORD') }}"
POSTGRES_HOST: "{{ env_var('POSTGRES_HOST') }}"
POSTGRES_PORT: "{{ env_var('POSTGRES_PORT') }}"
The env_var() is accessing the environmental variables that are defined in our mage-zoomcamp repository in the .env file. This allows us to later reference them in our data exporter in order to authenticate to our local postgreSQL instance.
Data Loader
Let's start by creating a pipeline and adding our first block, a python data loader.
Now that we've created our first Mage pipeline and data loader, we need to make some slight modifications to our script. It is best practice to define the datatypes prior to performing any transformations which is precisely what we've done using the taxi_dtypes as a dictionary object. The next variable we defined is parse_dates_yellow_taxi which is a list of date columns to be parsed. You may ask why we did not explicity declare the tpep_pickup_datetime and tpep_dropoff_datetime columns in our taxi_dtypes dictionary. The reason is date and time data come formatted in a variety of ways. The parse_dates parameter for the read_csv function instructs Pandas to automatically detect and parse these different formats into Python datetime objects. Without this, dates might be read as strings or other data types, which are less useful for time-based analyses. Simply put, if you try to parse datetime columns as datetime64 datatypes in taxi_dtypes it will throw an error, so use the parse_dates parameter instead!
import io
import pandas as pd
import requests
if 'data_loader' not in globals():
from mage_ai.data_preparation.decorators import data_loader
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@data_loader
def load_data_from_api(*args, **kwargs):
"""
Template for loading data from API
"""
url_yellow_taxi = 'https://github.com/DataTalksClub/nyc-tlc-data/releases/download/yellow/yellow_tripdata_2021-01.csv.gz'
url_green_taxi = 'https://github.com/DataTalksClub/nyc-tlc-data/releases/download/green/green_tripdata_2019-09.csv.gz'
taxi_dtypes = {
'VendorID': 'Int64',
'store_and_fwd_flag': 'str',
'RatecodeID': 'Int64',
'PULocationID': 'Int64',
'DOLocationID': 'Int64',
'passenger_count': 'Int64',
'trip_distance': 'float64',
'fare_amount': 'float64',
'extra': 'float64',
'mta_tax': 'float64',
'tip_amount': 'float64',
'tolls_amount': 'float64',
'ehail_fee': 'float64',
'improvement_surcharge': 'float64',
'total_amount': 'float64',
'payment_type': 'float64',
'trip_type': 'float64',
'congestion_surcharge': 'float64'
}
parse_dates_green_taxi = ['lpep_pickup_datetime', 'lpep_dropoff_datetime']
parse_dates_yellow_taxi = ['tpep_pickup_datetime', 'tpep_dropoff_datetime']
return pd.read_csv(url_yellow_taxi, sep=',', compression='gzip', dtype=taxi_dtypes, parse_dates=parse_yellow_green_taxi)
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'
Transformer
Now that we've defined our data loader, it's time to transform our data. This is where Transformation blocks in Mage come in to play. Adding one to our pipeline is fairly straight forward, we simply scroll down to the bottom of the most recent block and click Transformer which will create a new transformation block with whichever name we decide to use, I called mine transform_taxi_data.
Now that the block has been created, we need to apply a few simple filters to the taxi data we have loaded. The key transformation here is non_zero_passengers_df which essentially filters out any row in the dataset where the passenger count is zero. We also perform a count on the number of records where the passenger_count is not zero in the non_zero_passengers_count dataframe, priopr to returning the non_zero_passenger_df to be passed to the Data Exporter block.
if 'transformer' not in globals():
from mage_ai.data_preparation.decorators import transformer
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
import pandas as pd
@transformer
def transform(data, *args, **kwargs):
# Specify your transformation logic here
zero_passengers_df = data[data['passenger_count'].isin([0])]
zero_passengers_count = zero_passengers_df['passenger_count'].count()
non_zero_passengers_df = data[data['passenger_count'] > 0]
non_zero_passengers_count = non_zero_passengers_df['passenger_count'].count()
print(f'Preprocessing: records with zero passengers: {zero_passengers_count}')
print(f'Preprocessing: records with 1 passenger or more: {non_zero_passengers_count}')
return non_zero_passengers_df
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output['passenger_count'].isin([0]).sum() == 0, 'There are rides with zero passengers'
Data Exporter
Finally, it is time to export our data! This step is fairly straight forward, add a Data Exporter block similair to how we added our data loader and transformer. I've named mine ingest_taxi_data_postgres. In this data exporter, we define 3 variables, schema_name, table_name and config_profile. schema_name and table_name will be later used to query our postgreSQL database. i.e., SELECT * FROM ny_taxi.yellow_taxi_data. Setting the config_profile profile to dev instead of default allows us to access the dev profile in the io_config.yaml in which we previously defined our postgreSQL connection details.
from mage_ai.settings.repo import get_repo_path
from mage_ai.io.config import ConfigFileLoader
from mage_ai.io.postgres import Postgres
from pandas import DataFrame
from os import path
if 'data_exporter' not in globals():
from mage_ai.data_preparation.decorators import data_exporter
@data_exporter
def export_data_to_postgres(df: DataFrame, **kwargs) -> None:
schema_name = 'ny_taxi' # Specify the name of the schema to export data to
table_name = 'yellow_taxi_data' # Specify the name of the table to export data to
config_path = path.join(get_repo_path(), 'io_config.yaml')
config_profile = 'dev'
with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader:
loader.export(
df,
schema_name,
table_name,
index=False, # Specifies whether to include index in exported table
if_exists='replace', # Specify resolution policy if table name already exists
)
Execute Pipeline
Now that we've created our ETL pipeline and added all of the necessary blocks, it is time to execute our pipeline! Let's take a look at our finished DAG (Directed Acyclic Graph), which is a fancy way of describing a tree view of our pipeline, its blocks and dependencies, etc.
Note: you can drag in drop the block connections/dependencies in the tree view of Mage, which is useful when dealing with multiple pipeline blocks.
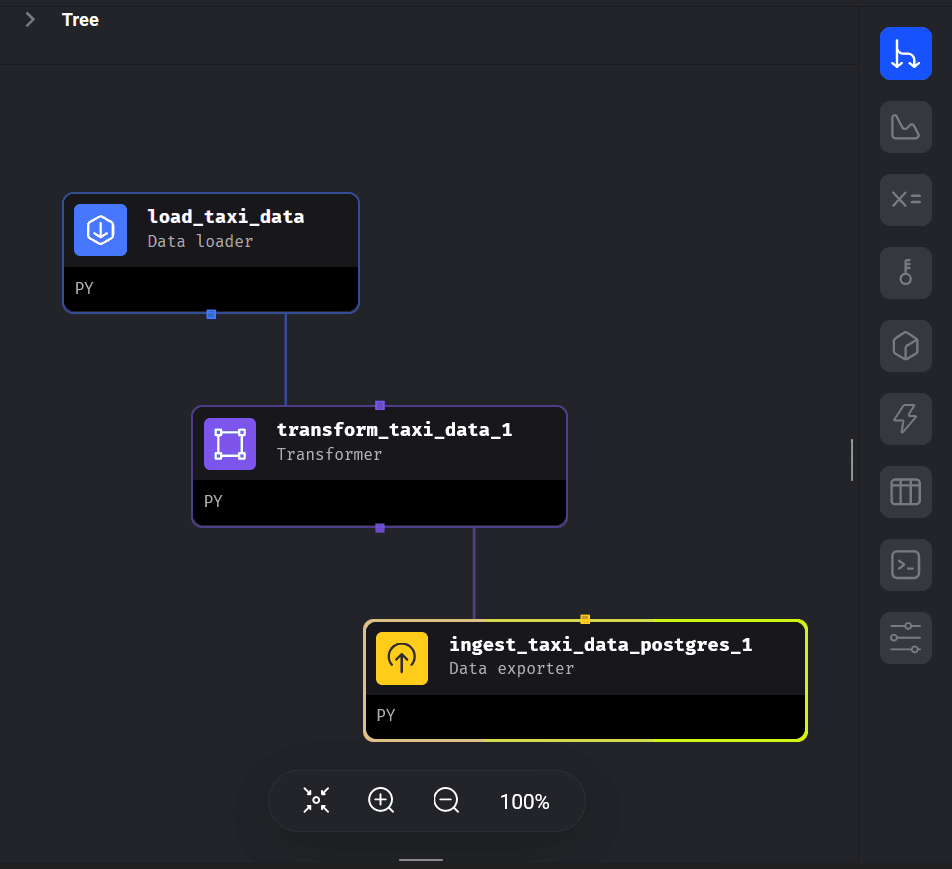
Now lets execute our pipeline! Right click the three dots in the top corner of the Data Exporter block and select Execute with all upstream blocks. This may take a few seconds to run due to the size of the dataset we are ingesting/exporting into postgreSQL.
Testing Pipeline Output (PostgreSQL)
Lastly, I added a data loader for the sake of testing the output of our pipeline. You can add one as well, by using a SQL Data Loader that Mage provides. Once you create the block, you'll need to configure the exporter to use PostgreSQL as it's connection and dev as the YAML profile. Then you can use the following command to query our newly created database.
SELECT * FROM ny_taxi.yellow_taxi_data LIMIT 10
Building an ETL Pipeline with Mage (Google Cloud)
Next up in the Week 2 module, we are tasked with creating an ETL pipeline similair to our first, the key difference being we are exporting our dataset to a Google Cloud Bucket instead of PostgreSQL. This requires a few additional steps that we will cover in the section below.
Create a cloud storage account
Create a service account
If you need a refresher on creating a GCP service account, you can refer back to my week 1 blog post here.
Download JSON keys
You will also need to download a JSON key in order to authenticate to our new service account, which I've also touched on in last weeks blog here.
Update Mage Configuration (Environmental Variables)
Now with our google cloud storage and service account created, we need to update the io_config.yaml file within the Mage repository either via the Mage GUI interface or vscode to source our newly created JSON keys.
Update the following YAML block under # Google by first deleting the GOOGLE_SERVICE_ACC_KEY variable and it's child properties.
GOOGLE_SERVICE_ACC_KEY:
type: service_account
project_id: project-id
private_key_id: key-id
private_key: "-----BEGIN PRIVATE KEY-----\nyour_private_key\n-----END_PRIVATE_KEY"
client_email: your_service_account_email
auth_uri: "https://accounts.google.com/o/oauth2/auth"
token_uri: "https://accounts.google.com/o/oauth2/token"
auth_provider_x509_cert_url: "https://www.googleapis.com/oauth2/v1/certs"
client_x509_cert_url: "https://www.googleapis.com/robot/v1/metadata/x509/your_service_account_email"
GOOGLE_SERVICE_ACC_KEY_FILEPATH: "/path/to/your/service/account/key.json"
GOOGLE_LOCATION: US # Optional
What's left should be
GOOGLE_SERVICE_ACC_KEY_FILEPATH: "/path/to/your/service/account/key.json"
GOOGLE_LOCATION: US # Optional
Now you can copy the JSON key in your downloads folder over to the Mage-Zoomcamp repo we are working out of. When you switch over to the Terminal in Mage and run shell ls -la you should see your JSON key within the directory. This is because in docker-compose.yml we mounted the volume:
volumes:
- .:/home/src/
So the code underneath the # Google block in io_config.yml should look as follows:
GOOGLE_SERVICE_ACC_KEY_FILEPATH: "/home/src/dtc-de-zoomcamp-12345678.json"
GOOGLE_LOCATION: US # Optional
Just to clarify, these yaml variables should be added under the default profile and not the dev profile we previously created.
Testing Mage connection to GCP
Now that we've tested our connection to GCP is working, we will want to create a new pipeline for the sake of ingesting our NY taxi data into GCP. I've named my pipeline ingest_taxi_data_gcp.
This is where Mage begins to shine, because we already have reusable code blocks that we previously created in our ingest_taxi_data_postgres pipeline that we can drag and drop into our new pipeline.
Let's give it a try!
After adding the load_api_data block, we need to add our transformation block as well as our data exporter block.
We will need to create a new Data Exporter block in order to ingest our taxi data into our Google Cloud Storage container. Be sure to select Python > Google Cloud Storage when creating the exporter.
Finally, one thing I've noticed when reusing a code block that was previously created in another pipeline, it is not automatically tied as a dependency to the other blocks we created, therefore we need to connect it as a dependcy via drag and drop in the tree view. I named my exporter taxi_data_to_gcs_parquet.
Now that we've connected all of the blocks, we must modify the code in our Data Exporter, taxi_to_gcs_parquet, to match the name of the cloud storage bucket we set up earlier.
bucket_name = 'your_bucket_name'
object_key = 'ny_taxi_data.parquet'
Once the variables have been updated, we can now run our pipleine. To do this, click the 3 dots in the top corner of the taxi_to_gcs_parquet block and select Execute with all upstream blocks, which runs everything in sequential order.
After you run the pipeline, be sure to check your storage bucket to confirm the output is as expected. It should look as follows:
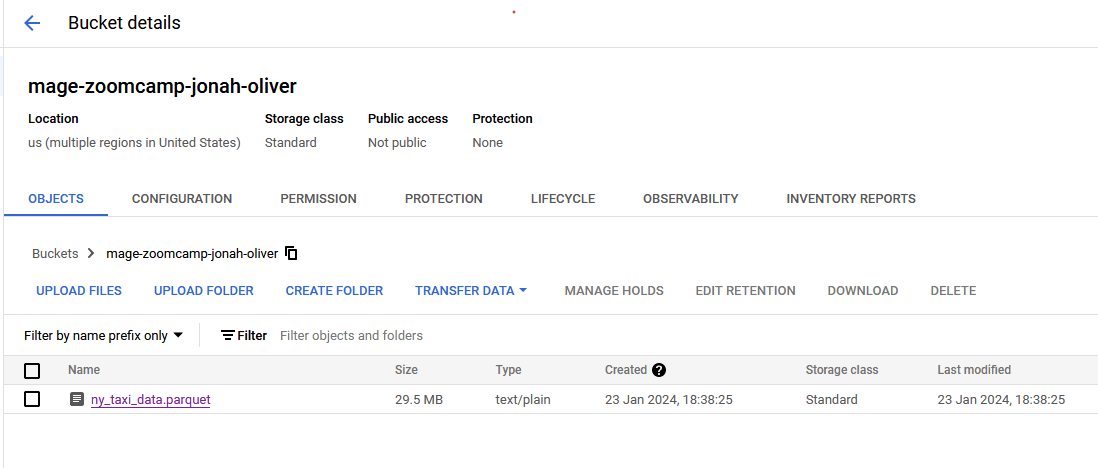
Partitioning with Parquet Files
Like most things, no two datasets are created equal. A solution that works for ingesting a smaller dataset may not be optimal for a much larger dataset or a dataset that will increase in scale as time passes. This is why chunk sizing can be a useful tool when dealing with larger files. In the Week 1 Module, we explicity implement chunk sizing with a for loop to slice our dataframe into smaller sections and ingest the chunks sequentially, which is better for memory management and effeciency in general. If you are curious of how this is implemnted, you can look back at the following section of my week 1 blog post.
In our current module, we implement another concenpt that isn't necessarily identical, but came to mind when I was going through this module. In the following section, we utilize the pyarrow python library, except instead of chunk sizing (dividing a dataset into smaller subsets where each chunk contains a fixed number of records or rows) we are applying column partitioning (dividing datasets based on the values of one or more columns).
The result is instead of ingesting one file into our cloud storage bucket ny_taxi_data.parquet, we ingest multiple in the form of partitioned parquet files by date, the file structure would look something like the following:
ny_taxi_data/
tpep_pickup_date=2021-01-01/
tpep_pickup_date=2021-01-02/
tpep_pickup_date=2021-01-03/
...
...
Let's implement this! First, create a Data Exporter and attach it to our Transformer block. We can run this in parallel with the previous Data Exporter we created. You can name the new exporter block something like taxi_to_gcs_partitioned_parquet and the python code should look as follows (be sure to update the variables to reflect the project id of your GCP project, the bucket name, etc.):
import pyarrow as pa
import pyarrow.parquet as pq
from pandas import DataFrame
import os
if 'data_exporter' not in globals():
from mage_ai.data_preparation.decorators import data_exporter
# update the variables below
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/home/src/dtc-de-zoomcamp-12345-de12345678.json'
project_id = 'dtc-de-zoomcamp-12345'
bucket_name = 'mage-zoomcamp-jonah-oliver'
object_key = 'ny_taxi_data.parquet'
table_name = 'ny_taxi_data'
root_path = f'{bucket_name}/{table_name}'
@data_exporter
def export_data_to_google_cloud_storage(df: DataFrame, **kwargs) -> None:
# creating a new date column from the existing datetime column
df['tpep_pickup_date'] = df['tpep_pickup_datetime'].dt.date
table = pa.Table.from_pandas(df)
gcs = pa.fs.GcsFileSystem()
pq.write_to_dataset(
table,
root_path=root_path,
partition_cols=['tpep_pickup_date'],
filesystem=gcs
)
Scheduling a Workflow (Automating Pipeline)
A key component in Data Orchestration is scheduling our workflows, in other words, automating our pipelines to run based on triggers. Mage defines three triggers that I'm aware of:
- Schedule
- Event
- API
We can add a Schedule Trigger to automate our pipeline to run just once, daily or even on an hourly cadence.
Parameterization
If you recall back to the python ingestion script we wrote in week 1, we used the python library argparse to pass in arguments or parameters into our python script upon running the docker container in the command terminal. Parameters such as our username, password, database, table and the url of our taxi data csv file. The alternative to this is to define these parameters as variables in the python script itself, but parameterizing our pipelines allows us more flexibility.
Parametrization can allow us to call a pipeline on demand for a specified date. Perhaps we notice some missing data in a SQL database which is serving as a data store for an automated pipeline. One way you could go about handling this is to add a date parameter that you can pass into a script which will allow you to execute a pipeline for that specific date. This is generally know as backfilling which is covered later in this module. There are methods to automating backfilling, but I like to use it as an example to explain paramterization.
We can use parameters within Mage, similair to how we've previously implemented it, but with some slight differences.
Let's add an additional Data Exporter to our pre-existing pipeline so we can implement some parameters. The parameter we are adding is the execution_date which is a built in parameter that is created when executing the pipeline code. We are assigning the execution date to a variable named now and then using the strftime() function, which stands for "string format time", to convert a datetime object into a string format of our choosing. This can be useful for applying a consistent naming format to our files for storage. Be sure to check your cloud storage container to see resulting filepath of our pipeline output.
Pro tip: You can use the shortcut commands CTRL-K-C & CTRL-K-U to comment out blocks of code at a time. Use CTRL-K-C to uncomment the commented out block of code below when you are ready for the script to export your data.
from mage_ai.settings.repo import get_repo_path
from mage_ai.io.config import ConfigFileLoader
from mage_ai.io.google_cloud_storage import GoogleCloudStorage
from pandas import DataFrame
from os import path
if 'data_exporter' not in globals():
from mage_ai.data_preparation.decorators import data_exporter
@data_exporter
def export_data_to_google_cloud_storage(df: DataFrame, **kwargs) -> None:
now = kwargs.get('execution_date')
print(now) # Output: '2024-01-25 18:42:18.783257' (example output)
now_fpath = now.strftime('%Y/%m/%d')
print(now_fpath) # Output: '2024/01/25' (example output)
bucket_name = 'mage-zoomcamp-jonah-oliver'
object_key = f'{now_fpath}/daily-trips.parquet'
print(object_key) # Output: 2024/01/25/daily-trips.parquet (example output)
config_path = path.join(get_repo_path(), 'io_config.yaml')
config_profile = 'default'
# GoogleCloudStorage.with_config(ConfigFileLoader(config_path, config_profile)).export(
# df,
# bucket_name,
# object_key,
# )
In Summary
This week's journey through the Data Engineering Zoomcamp has taken us deep into the heart of workflow orchestration with Mage. We've explored:
- The Fundamentals of Workflow Orchestration: Understanding how Mage, much like a meticulous chef in a kitchen, helps us define, organize, and execute tasks in a precise order.
- **Building an ETL Pipeline: We walked through constructing an efficient ETL pipeline using Mage, highlighting the integration with Python, PostgreSQL and Google Cloud Storage for effective data handling.
- Advanced Concepts: Delving into partitioning with Parquet files and pipeline scheduling, we touched upon more advanced topics that will further enhance our engineering skills.
Looking Ahead
I hope this post has been insightful to anyone struggling with the Zoomcamp. I'm looking forward to diving into the Week 3 content and sharing what I've learned here in future posts to come.